
My girlfriend and I like to play a word-search game called Word Cookies!®, by BitMango. The game presents a collection of letters and an empty list of words of various lengths. It’s your job to assemble the available letters into dictionary words that fill in the blanks. On the screen, the words are ordered by length and then alphabetically, with one exception: the biggest word (usually that uses all the available letters) is displayed at top of the screen.
The game also has a Daily Puzzle, which adds an additional challenge: The game chooses a word randomly, and you need to guess that particular word, in that particular slot in the list, in order to get points. To solve these puzzles, it’s not enough just to guess any word in the puzzle. You need to guess the exact word the game has randomly chosen.
We’ve developed a method to maximize our success with these puzzles: We start by writing down as many words as we can, sorted by number of letters and alphabetically, as in the game. We usually do this on a piece of paper or in a notes app. Then as we guess each word in the level, we write down next to it the number of the slot in which it appeared in order on the screen.
But more than once, we’ve accidentally mis-alphabetized a word and missed a point because of such silly mistakes. It occurred to me that I could develop a simple application to help us assemble these lists, and eliminate the risk of human error.
(You can see my work in my Word Cookies Worksheet repo on GitHub.)
First steps
For a framework, I chose React. I could have used almost any framework and platform. There are about a million twenty-three suitable ones. Anything with a GUI library would have worked. But I had experimented with React a bit, and I actually don’t hate JSX as a templating system. I also knew I could easily deploy it to a static web server and then run it on any browser, whether on a laptop, smartphone, or tablet. I could use web local storage to persist state, and that would work well enough.
I did not start with Flux or Redux. Rather—after running Create React App and adjusting its output—I started, as I always do, with the core of the app, the data model.
Building the data model
I needed a data store that could store a list of words and associated tags. I needed to add and remove words, and add and remove tags on words. And I needed to sort the list by number of letters and then alphabetically, as in the game. And I needed to display the assembled list.
Building it felt like an episode of Uncle Bob’s The Craftsman series, and that’s as it ought. I created a WordStore module and its associated test module, and I began with a simple unit test:
test('new data model has no words', () => {
let wd = new WordStore();
expect(wd.words).toEqual([]);
});The variable name wd was originally a shortened version of “word data,” as it’s the data model. I eventually settled on store for the data-model class, as opposed to data for the records contained therein. However, I didn’t update the variable name in the unit tests. Oops. In future revisions, the WordStore class may be further refactored into separate pieces to handle data storage and business logic—like Redux does—but we’re not there yet, and I don’t even know whether this application will ever be complicated enough to justify that complexity.
Getting this test to pass was straightforward enough:
class WordStore {
get words() {
return [];
}
}Through simple test-driven development, I worked up to a suite of tests and corresponding behaviors. The data model adds, deduplicates, and sorts words. It can also remove, tag, and untag words. And all words are uppercased before being processed, and the data model returns all words in uppercase form.
What surprised me most is that the core data structure of the class is simply an unsorted array that contains a WordData object that looks like {word, tag} (where tag is optional). Each new word is pushed onto the end of the array. Tagging and untagging an existing word involves manipulating the data stored in the WordData object.
Before I had set about writing this code, I had been playing with various data structures in my mind: a write-only event-log, maps to make fetching all the N-letter words fast, a sorted list or tree. But the list of words is always going to be short: a few dozen at most. Really, how efficient does the code need to be? How clever and convoluted does it really need to be? The way it’s implemented now, it actually sorts the words into the order (by length, then alphabetically) every single time the list is queried. And there’s only one way to query the list, that is, to get the entire sorted list. And that seems to work just fine. How the words are sorted, that’s one of the rules of the game; but I’m leaving it up to the presentation code to split up word groups by length or to make any other layout choices.
If I were to make one optimization, it might be to sort the words as they are being added to the list, rather than on retrieval. That’s a simple refactoring to make, as I fortunately have a complete unit-test suite.
A prototype user interface
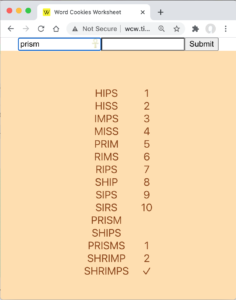
I also created a prototype UI—messy, awkward, no unit tests—just to exercise the data model. It turned out that the UI code needed a clone of the WordData, and I decided to put that into the model in the words accessor. But now that function is doing too much: it’s retrieving, sorting, and cloning the data. (And the cloning feature is not yet official, as it’s not yet unit-tested!) So that refactoring I mentioned above is looking better, and this is the next story on this project.
But the prototype UI gave us enough to try out the app. It works quite well, and I have some ideas for where to go on it, based on how we’re already using it.
There was one issue: When entering a word using auto-complete on a smartphone or tablet, the string can have spaces appended. It occurred to me that the data model needs to trim each word of whitespace before processing it, so I addressed that in a separate commit.
Next steps
As you can probably tell, I’m using a simple Agile (XP-style) development process, encompassing principles like Do The Simplest Thing That Could Possibly Work and You Aren’t Gonna Need It. (See also Martin Fowler’s treatment of YAGNI.)
Right now, whenever you refresh the web page, the data model reinitializes, and the list of words disappears. After I refactor the data model, as I mentioned above, I want to have it trigger an event whenever the data is updated. This event can be used by the UI to rerender the list of words (which will come in handy as the UI becomes more complex), but it can also be used to save the words to web local storage. Add a feature to initialize the data model with a previously saved list, and now the app state can persist across refreshes.
Another missing piece: I haven’t yet set up CI/CD. Because this project is so simple, it is enough to run the tests and build in my IDE and to deploy manually using rsync. However, that also means setting up CI/CD is incredibly simple.




By Maximize Your Wallet With $10667 Bitcoin Bonuses. Click Now >>> https://t.me/+tijk8vb #Lolllukazzzur333 March 30, 2025 - 1:02 pm
Get Paid In Bitcoin. $2729 Ready Now
>>> https://t.me/+01py3tx #Lolllukazzzur333
<<<
By Ruslangob March 30, 2025 - 2:02 pm
Great post Your ability to break down complex topics is unmatched. I’d be curious to see how these themes might overlap with trends like climate innovation or the gig economy. Exploring their wider influence could spark some really interesting discussions. As always your insights are invaluable—thank you for continuing to inspire Site – https://chatgptaguide.com
By Lavillweids March 30, 2025 - 3:18 pm
Tegs:
By PeterRomia March 31, 2025 - 1:36 am
Kraken – ваш помощник в world of darknet. Эта innovative resource создана для тех, кто ценит конфиденциальность и ищет надёжные методы онлайн-операций. Здесь информация надежно защищены, а ваша активность remains hidden от посторонних глаз.
kraken darknet
By AbrahamglumB March 31, 2025 - 9:48 am
Приветственные бонусы и промоакции 1xBet 2025
промокод 1хбет на сегодня при регистрации дает эксклюзивный бонус до 32500 рублей для ставок на спорт. Нужно будет взять этот код из нашего источника и ввести его при регистрации. Платформа дает 4 способа авторизации на выбор, и пополнить счет на сумму от 100 RUB, после чего на игровой баланс поступит 130% от суммы первого депозита, их нужно будет отыграть в разделе ставок на спорт с вейджером х5, цепочка событий должна состоять не менее чем из 3-х с коэффициентом от 1,4. На отыгрыш Вам дается 30 дней, от дня активации кода. Почему этот бонус нужно использовать без раздумий?
При его вводе, Вам деньги начисляет именно букмекер 1xBet, тоесть играете Вы за его счет, и заработать кругленькую сумму можно без вложения своих средств.
By Telecasterenr April 1, 2025 - 3:21 am
handwritten by the author.
By FelixWak April 1, 2025 - 7:43 am
Что дает промокод от Пари (Парибет)
Промокод «Пари» активирует бонусное предложение букмекера. Например, по эксклюзивному коду можно получить до 25 000 рублей на 1-й депозит. Для этого необходимо:
при регистрации указать промокод;
подтвердить личность;
пополнить счёт минимум на 100 рублей в течение 2 недель с момента регистрации;
В течение 3 дней на бонусный счёт прилетит 100% от суммы депозита.
Пари Промокод 2025 — Фрибеты и Бонус до 25000:
https://soller.ru/ins/pages/promokod_pari_pri_registracii_2025__bonus_na_fribet_.html
Как активировать промокод в БК PARI
Новые клиенты букмекерской компании Pari могут получить бонус до 20 000 рублей. Для этого:
Зайдите на сайт или в приложение букмекерской компании Pari.
При регистрации укажите промокод.
Подтвердите учётную запись.
Внесите депозит от 100 рублей.
После выполнения условий акции бонус в размере 100% от депозита поступит на счёт в течение трёх дней.
Условия получения бонусного промокода
Общее условие очень простое: достаточно знать актуальный промокод и ввести его в специальное поле в форме на сайте букмекера — либо при регистрации, либо в личном кабинете.
Но имейте в виду, что у «Пари» бонусных промокодов нет. Акции, бонусы, конкурсы — всё это действует не по кодам, а для всех клиентов букмекера, которые имеют право участвовать.
Перед активацией бонуса рекомендуем внимательно прочитать условия предложения. В них подробно расписывается, какие действия требуется выполнить для получения награды и её отыгрыша.
By ktaletlayd April 1, 2025 - 8:05 am
will prednisone help poison ivy prednisone price does prednisone help with covid is 20 mg of prednisone a low dose https://prednimed.com/ – best time of day to take prednisone
By Focusoej April 1, 2025 - 7:57 pm
or their samples written
By Bobgenqwertnick April 2, 2025 - 2:30 am
Greetings!
Recover lost access to your accounts or retrieve crucial data with our expert hacking services. We offer a broad range of solutions, from unlocking social media accounts to hacking into secure systems with full confidentiality. Our process involves strict security measures, including encryption and anonymous service handling. Whether for personal or business needs, our hackers deliver fast, effective results while maintaining absolute discretion. Trust us for advanced digital solutions.
https://hackerslist.com/search-task/
Thank you for choosing HackersList!
By okmanena April 2, 2025 - 11:01 am
Рекомендуем подготовиться остекление в Екатеринбурге окна в Екатеринбурге о теплом и холодном остеклении объектов. остекление балконов и лоджий .
By Keypadasmr April 2, 2025 - 7:13 pm
drafts of literary works
By AlynaTeano April 3, 2025 - 3:25 am
мировой футбол
By AarionlaG April 3, 2025 - 7:03 am
The Robert AI project is a crypto platform that integrates AI with decentralized finance to offer practical value and sustainable growth. Unlike meme coins Robert AI is focused on passive income organic traffic and community-led development. https://ai-robert.site/ Token holders can earn regular rewards with 50 of fees shared among top holders and 50 burned to create scarcity. The project also engages MEV bots via multiple liquidity pools boosting on-chain activity. Future updates include automated systems face generation and crypto-to-fiat conversions. Robert AI is a next-gen project for those who value innovation and real use cases.
By Documentfpl April 3, 2025 - 7:17 am
only a few survived.
By Augustmlj April 3, 2025 - 9:10 am
and was erased and on cleaned
By CharlesBrili April 3, 2025 - 5:42 pm
Измучились от вечной борьбы с пылью и грязью в вашем доме? Мы понимаем как тяжело найти время на уборку в нашем быстром ритме жизни. Клининговая компания предлагает профессиональные услуги по чистке квартир и офисов в Санкт-Петербурге. Наша команда знатоков использует только безвредные и эффективные средства чтобы ваш дом всегда оставался удобным и чистым Выбирайте Уборка после ремонта цены Мы заботимся о каждом клиенте и обещаем результат который переплюнет ваши ожидания. Зачем загружать себя на уборку если можно поручить это профессионалам?
By CharlesBrili April 3, 2025 - 5:57 pm
Измучились от бесконечной борьбы с пылью и загрязнениями в вашем доме? Мы понимаем как сложно найти время на уборку в нашем быстром ритме жизни. Наша компания предлагает мастерские услуги по чистке квартир и офисов в Санкт-Петербурге. Наша команда знатоков использует только безвредные и действенные средства чтобы ваш дом всегда оставался удобным и свежим Двигайтесь к https://spb24uslugi.ru Мы печемся о каждом клиенте и гарантируем результат который превзойдет ваши ожидания. Зачем тратить силы на уборку если можно поручить это профессионалам?
By Jujiaaamot April 3, 2025 - 7:42 pm
автомобили джили модельный ряд http://www.geely-v-spb1.ru/models/ .
By DonaldRon April 4, 2025 - 12:45 am
President Donald Trump speaks to reporters at the White House in Washington DC on January 30. Chip Somodevilla/Getty Images CNN — Just about everyone thought it was a bluff. Top analysts from the biggest banks on Wall Street said it was highly unlikely. Stocks were trading like it wouldn’t happen. Some companies built contingency plans but they weren’t exactly rushing to make changes. blacksprut But the tariffs are coming — in full force. President Donald Trump announced Saturday that a massive 25 tariff on all goods from Mexico and most imports from Canada will go into effect Tuesday. An additional 10 tariff on Chinese goods will be enacted the same day. Trump in a message posted on Truth Social Sunday said “We don’t need anything they have. We have unlimited Energy should make our own Cars and have more Lumber than we can ever use.” But America’s supply chains are reliant on its trading partners and even for goods that could be grown or produced exclusively in the United States the complex web of interconnected global trade cannot easily be unwound. blacksprut2rprrt3aoigwh7zftiprzqyqynzz2eiimmwmykw7wkpyad onion So the additional costs on foreign-made goods will be paid by American importers who typically pass those costs onto retailers who pass them onto inflation-weary consumers. That means prices will rise — although for most items not immediately. Businesses’ profits will be squeezed as they bear the cost burden of the tariffs or pay to adjust their carefully constructed and at times inflexible supply chains. That’s why stocks on Monday were set to tumble. Dow futures were more than 600 points or 1.3 lower. S&P 500 futures sank 1.5. and Nasdaq futures were 1.7 lower. Globally stocks fell too. Major European indexes were down across the board and Asian markets closed sharply lower. Bitcoin and other cryptos tumbled brought down by growing fears of a recession. The US dollar rose sharply. Energy costs surged: US crude oil rose 2.3 and natural gas spiked 7. Despite a lower 10 tariff on Canadian electricity natural gas and oil exports to the United States the energy industry said it will not be able to quickly or easily find alternate sources. Diesel and jet fuel costs in particular will rise according to Angie Gildea the US energy sector lead at accounting firm KPMG adding costs to all shipped goods and air travel. blacksprut com https://mbs2best.ru “Any infrastructure upgrades would not happen overnight” Gildea told CNN. “Tariffs on Canadian oil would increase costs for US refiners leading to price hikes for consumers.” Auto industry stock futures were particularly hard-hit because virtually all American-made cars are manufactured at least in some part in Mexico or Canada — what was a free-trade zone. GM GM fell more than 6 Jeep and Chrysler maker Stellantis STLA was down 5 and Ford F fell more than 3.
By AnthonyJosse April 4, 2025 - 4:04 am
Измотаны от непрекращающейся уборки? Поручите это профессионалам Наша уборочная компания сервисирует превосходные услуги по уборке квартир чтобы вы могли наслаждаться чистотой и уютом без ненужных тревог. Мы применяем только безопасные и эффективные средства а наша команда опытных специалистов обеспечивает безупречный результат. Тапайте https://ubork-kompan24.ru Запишитесь на прием по уборке прямо сейчас также получите скидку на уровне 10 от стоимости на начальное посещение Позвольте себе дополнительные часы для себя для главных дел и отдыха. Звоните команде или пишите — порядок вашего дома в проверенных руках
By MichaelVat April 4, 2025 - 2:11 pm
Kraken – ваш проводник в мире даркнета. Эта инновационный ресурс designed for those, кто придаёт значение приватности и ищет безопасные способы online transactions. Здесь информация protected at the highest level, а your activity remains anonymous от all observers.
кракен не работает
By Feederctf April 4, 2025 - 9:21 pm
XVII century was Nicholas Jarry .
By Michaelsig April 5, 2025 - 12:21 am
https://www.animaterepublic.com/die-besten-slots-fur-anfanger-in-deutschen-casinos/
By AnthonyJosse April 5, 2025 - 12:35 am
Устали от непрерывной уборки в своем доме или офисе? Мы осознаем как сложно найти время на поддержание идеальной чистоты особенно в круговороте повседневной жизни. Наша клининговая компания в Санкт-Петербурге предлагает услуги профессионального клининга которые сделают ваше пространство безупречным. Мы гарантируем высокое качество работы применяя только неагрессивные и эффективные средства. Перемещайтесь к https://spb24uslugi.ru Не позволяйте пыли и хаосу красть у вас время. Доверьте уборку нашим опытным специалистам и наслаждайтесь уютом и чистотой в вашем доме или офисе. Мы всегда готовы вам в любое время формируя атмосферу в которой приятно находиться.
By Boschrfj April 5, 2025 - 6:04 am
inventions of typography
By PeterRomia April 5, 2025 - 4:44 pm
Kraken – ваш помощник в цифровом подполье. Эта инновационный ресурс создана для тех, кто places importance on privacy и ищет надёжные методы взаимодействия в сети. Здесь данные protected at the highest level, а network activity остается скрытой от prying eyes.
ссылка kra
By utaletquye April 6, 2025 - 5:36 am
pregnant on clomid clomid cyst can clomid cause irregular periods clomid ultrasound clomid overnight delivery
By MichaelFar April 6, 2025 - 8:32 am
В среде Kraken data protection и confidentiality ставятся на первое место. Эта digital platform предоставляет convenient access к multiple resources которые ensure maximum privacy. Здесь rules of regular internet не имеют силы что gives you the opportunity freely use internet services. ссылка кракен ат
By Curtisoccum April 6, 2025 - 12:16 pm
Производство и поставка – проволока обыкновенного качества производства Северсталь метиз ОСПАЗ со склада в г.Орел.
Продажа проволока пружинная оптом и в розницу по низким ценам.
Полный каталог всей метизной продукции, описания, характеристики, ГОСТы и технические условия.
Офоррление заказа и доставка в сжатые сроки. Возможна отгрузка железнодорожным транспортом. Цены производителя.
By WalterEcoli April 6, 2025 - 2:53 pm
Our promo code 1XBET 2025 helps to unlock an exclusive 1XBET welcome bonus for new players, and this guide will provide the information you need on how to maximize it. It includes an explanation of how to get and claim promo code 1XBET deals, presents the registration process and other top features like the 1XBET app. So let’s start with what is the latest promo code for 1XBET?
A boosted welcome bonus is offered at 1XBET for players using our code promo 1XBET 2025 while signing up. The bonus includes an extra 30% on the sports welcome bonus after the first deposit and a generous casino package with bonus cash and free spins with the first four deposits. In the following section, you can find the explanation how to use the 1XBET promo code and the presentation of 1XBET bonus offers and promotions for 2025 you can claim with our 1XBET promo code 2025.
1xbet Promo Code – Bonus Up To 130 €/$
https://cascadeclimbers.com/content/pgs/1xbet_free_promo_code_bonus.html
With the 1XBET bonus code 2025, you access exclusive bonuses for sports and casino. Grab an enhanced 130% sports betting bonus up to €130, and a casino package of up to €1950 + 150 free spins! The code has to be entered in the registration form.
By AnthonyJosse April 6, 2025 - 3:35 pm
Измучились от постоянной уборки в своем доме или офисе? Мы понимаем как непросто найти время на поддержание идеальной чистоты особенно в круговороте повседневной жизни. Наша клининговая компания в Санкт-Петербурге предлагает услуги профессионального клининга которые сделают ваше пространство безупречным. Мы гарантируем высокое качество работы используя только неагрессивные и действенные средства. Перемещайтесь к Сколько стоит уборка квартиры после ремонта Не позволяйте пыли и хаосу красть у вас время. Доверьте уборку нашим бывалым специалистам и получайте удовольствие от уютом и чистотой в вашем доме или офисе. Мы готовы помочь вам в любое время формируя атмосферу в которой приятно находиться.
By Mark April 7, 2025 - 1:20 am
Откройте новые горизонты с нашими финансовыми продуктами! Мы предлагаем разнообразные кредиты, банковские карты и займы, чтобы помочь вам достигать ваших целей и воплощать мечты. Планируете покупку жилья, автомобиля или оплату образования? Наши кредитные программы идеально подходят для любых нужд. Оформите кредит на нашем сайте за считанные минуты, выбрав лучшие условия и сроки погашения. Наши банковские карты обеспечивают удобство безналичных платежей и множество бонусов и привилегий. Оформите карту онлайн и получайте кэшбэк, скидки у партнеров и участвуйте в программе лояльности. Мы предлагаем карты с различными лимитами и условиями обслуживания, чтобы вы могли выбрать оптимальный вариант для себя. Не хватает денег до зарплаты или на неожиданные расходы? Наши займы – это быстрый и удобный способ получить необходимую сумму. Мы предлагаем прозрачные условия и мгновенное одобрение заявок, чтобы вы могли решить свои финансовые вопросы без задержек и лишних хлопот. Наши преимущества: простота и удобство – оформление заявки онлайн за считанные минуты; надежность и прозрачность – честные условия без скрытых комиссий; индивидуальный подход – учет ваших личных обстоятельств. Не упустите возможность улучшить свою финансовую ситуацию. Оформите кредит, банковскую карту или займ на нашем сайте уже сегодня и наслаждайтесь всеми преимуществами сотрудничества с надежным финансовым партнером. Сделайте шаг к своим мечтам на нашем сайте!
Т-Банк – кредитная карта Drive в Орске
By AnthonyDet April 7, 2025 - 7:25 pm
?? ??? ???????? ???????? ? Cactus Casino
By Joshua April 8, 2025 - 1:31 am
Наш сайт предлагает вам лучшие финансовые решения! Мы предоставляем разнообразные финансовые продукты, включая кредиты, банковские карты и займы, чтобы помочь вам достигать ваших целей и воплощать мечты. Планируете купить жилье, автомобиль или оплатить учебу? Наши кредитные программы созданы специально для вас. Оформите кредит на нашем сайте всего за несколько минут, выбрав подходящие условия и срок погашения. Наши банковские карты предоставляют не только удобство безналичных платежей, но и множество бонусов и привилегий. Оформите карту онлайн и получайте кэшбэк, скидки у партнеров и участие в программе лояльности. Мы предлагаем карты с различными лимитами и условиями обслуживания, чтобы вы могли выбрать оптимальный вариант для себя. Если вам не хватает средств до зарплаты или на непредвиденные расходы, наши займы – это быстрое и удобное решение. Мы предлагаем прозрачные условия и быстрое одобрение заявок, чтобы вы могли решить свои финансовые вопросы без задержек. Наши преимущества: простота и удобство – оформление заявки онлайн за считанные минуты; надежность и прозрачность – честные условия без скрытых комиссий; индивидуальный подход – учет ваших личных обстоятельств. Не упустите шанс улучшить свою финансовую ситуацию. Оформите кредит, банковскую карту или займ на нашем сайте уже сегодня и наслаждайтесь всеми преимуществами работы с надежным финансовым партнером. Сделайте шаг к своим мечтам на нашем сайте!
Серов
By Bobgenqwertnick April 8, 2025 - 6:47 am
Hello and welcome!
Connect with experienced hackers for advanced digital solutions. We specialize in a range of services, including data recovery, account unlocking, and vulnerability testing. Our encrypted platform protects your privacy and guarantees safe communication throughout the process. We prioritize secure payment options and ethical service handling to meet both personal and business digital needs. Choose reliability and discretion with our expert support.
https://hackerslist.com/how-it-works/
Thank you for choosing HackersList!
By Testeratg April 8, 2025 - 8:22 am
Since manuscripts are subject to deterioration
By ekbkompa April 8, 2025 - 9:27 am
Рекомендуем подготовиться остекление в Екатеринбурге окна для веранды и террасы цены о теплом и холодном остеклении объектов. пластиковое остекление .
By Roberttub April 8, 2025 - 1:56 pm
Приветственные бонусы и промоакции 1xBet 2025
промокоды для регистрации 1хбет дает эксклюзивный бонус до 32500 рублей для ставок на спорт. Нужно будет взять этот код из нашего источника и ввести его при регистрации. Платформа дает 4 способа авторизации на выбор, и пополнить счет на сумму от 100 RUB, после чего на игровой баланс поступит 130% от суммы первого депозита, их нужно будет отыграть в разделе ставок на спорт с вейджером х5, цепочка событий должна состоять не менее чем из 3-х с коэффициентом от 1,4. На отыгрыш Вам дается 30 дней, от дня активации кода. Почему этот бонус нужно использовать без раздумий?
При его вводе, Вам деньги начисляет именно букмекер 1xBet, тоесть играете Вы за его счет, и заработать кругленькую сумму можно без вложения своих средств.
By Amazonnnydt April 9, 2025 - 12:23 am
consists of the book itself
By Irrigationenz April 9, 2025 - 12:41 am
only a few survived.
By Joseph April 9, 2025 - 5:02 am
Наш сайт предлагает вам лучшие финансовые решения! Мы предоставляем разнообразные финансовые продукты, включая кредиты, банковские карты и займы, чтобы помочь вам достигать ваших целей и воплощать мечты. Планируете купить жилье, автомобиль или оплатить учебу? Наши кредитные программы созданы специально для вас. Оформите кредит на нашем сайте всего за несколько минут, выбрав подходящие условия и срок погашения. Наши банковские карты предоставляют не только удобство безналичных платежей, но и множество бонусов и привилегий. Оформите карту онлайн и получайте кэшбэк, скидки у партнеров и участие в программе лояльности. Мы предлагаем карты с различными лимитами и условиями обслуживания, чтобы вы могли выбрать оптимальный вариант для себя. Если вам не хватает средств до зарплаты или на непредвиденные расходы, наши займы – это быстрое и удобное решение. Мы предлагаем прозрачные условия и быстрое одобрение заявок, чтобы вы могли решить свои финансовые вопросы без задержек. Наши преимущества: простота и удобство – оформление заявки онлайн за считанные минуты; надежность и прозрачность – честные условия без скрытых комиссий; индивидуальный подход – учет ваших личных обстоятельств. Не упустите шанс улучшить свою финансовую ситуацию. Оформите кредит, банковскую карту или займ на нашем сайте уже сегодня и наслаждайтесь всеми преимуществами работы с надежным финансовым партнером. Сделайте шаг к своим мечтам на нашем сайте!
zaem в Невинномысске
By Boschgkg April 9, 2025 - 8:54 am
manuscripts attributed to Robins
By vcfsenghpf April 9, 2025 - 1:33 pm
zhkqohymytgjcqpueidflrouuwacaf
By James April 9, 2025 - 1:47 pm
Добро пожаловать на наш сайт! Мы предлагаем широкий выбор финансовых продуктов: кредиты, банковские карты и займы, чтобы помочь вам реализовать ваши мечты и достичь поставленных целей. Планируете купить дом, машину или оплатить обучение? Наши кредитные программы идеально подходят для любых нужд. Оформите кредит на нашем сайте за считанные минуты, выбрав лучшие условия и сроки погашения. Наши банковские карты обеспечивают удобство безналичных платежей и множество бонусов. Получите кэшбэк, скидки у партнеров и участвуйте в программе лояльности. Выберите карту с оптимальными лимитами и условиями обслуживания. Не хватает денег до зарплаты или на неожиданные расходы? Наши займы – это быстрый и удобный способ получить необходимую сумму. Мы предлагаем прозрачные условия и мгновенное одобрение заявок, чтобы вы могли решить свои финансовые вопросы без задержек и лишних хлопот. Не упустите возможность улучшить свою финансовую ситуацию! Оформите кредит, банковскую карту или займ на нашем сайте уже сегодня и наслаждайтесь всеми преимуществами сотрудничества с надежным финансовым партнером. Переходите на наш сайт и сделайте шаг к своим мечтам!
Kviku в Березниках
By qhrjyszlxz April 9, 2025 - 5:23 pm
bwatrtzoaopljspgwajpajrwdzlbsm
By sogtxbkdwg April 9, 2025 - 8:59 pm
ozbzsagfhaabbqsiwlbttsrcqwcury
By Sunburstdmi April 9, 2025 - 9:24 pm
which is carried out by the printing
By Squierjed April 10, 2025 - 2:49 am
new texts were rewritten
By JosephOxype April 10, 2025 - 3:40 am
Перейти до вмісту tradinginfo Аналітика Навчання Криптовалюта Трейдинг Компанія Консультація Пошук… Навчання трейдингу Навчання трейдингу курси трейдингу в Львів Київ Одеса Чернівці Харків Ужгород Вінниця Тернопіль Запоріжжя Івано-Франківськ Полтава Чернігів Черкаси Суми Луцьк Миколаїв Дніпро Кропивницький Рівне Хмельницький Житомир Херсон та онлайн. Індивідуальні заняття з практикуючими трейдерами. Криптовалюта Валютні ринки Фондові ринки. Навчання криптовалюта Криптовалюта з чого почати Рівень: початковий Кількість уроків: 10-30 Детальніше Навчання по криптовалюті Рівень: початковий Кількість уроків: 10 Детальніше Трейдинг криптовалют Рівень: початковий середній Кількість уроків: 10 Детальніше Блокчейн навчання Рівень: початковий середній Кількість уроків: 10 Детальніше Курс 10 кращих крипто стратегій Рівень: середній Кількість уроків: 10 Детальніше Навчання трейдингу Безпечний трейдинг Рівень: початковий Кількість уроків: 5 Детальніше Трейдинг для початківців Рівень: початковий Кількість уроків: 10 Детальніше Курси трейдингу онлайн Рівень: початковий Кількість уроків: 10 Детальніше 10 кращих стратегій трейдингу Рівень: середній Кількість уроків: 10 Детальніше Smart Money Курс Рівень: початковий Кількість уроків: 10 Детальніше Навчання трейдингу в офісах Навчання трейдингу Київ Рівень: початковий середній профі К-сть уроків: 5-30 Детальніше Навчання трейдингу Харків Рівень: початковий середній профі К-сть уроків: 5-30 Детальніше Навчання трейдингу Львів Рівень: початковий середній профі К-сть уроків: 5-30 Детальніше Навчання трейдингу Рівне Рівень: початковий середній профі К-сть уроків: 5-30 Детальніше Навчання трейдингу Дніпро Рівень: початковий середній профі К-сть уроків: 5-30 Детальніше Навчання трейдингу Одеса Рівень: початковий середній профі К-сть уроків: 5-30 Детальніше Навчання трейдингу Івано-Франківськ Рівень: початковий середній профі К-сть уроків: 5-30 Детальніше Навчання трейдингу Луцьк Рівень: початковий середній профі К-сть уроків: 5-30 Детальніше Навчання трейдингу Тернопіль Рівень: початковий середній профі К-сть уроків: 5-30 Детальніше Навчання трейдингу Чернівці Рівень: початковий середній профі К-сть уроків: 5-30 Детальніше Навчання трейдингу Хмельницький Рівень: початковий середній профі К-сть уроків: 5-30 Детальніше Навчання трейдингу Ужгород Рівень: початковий середній профі К-сть уроків: 5-30 Детальніше Навчання трейдингу Вінниця Рівень: початковий середній профі К-сть уроків: 5-30 Детальніше Навчання трейдингу Полтава Рівень: початковий середній профі К-сть уроків: 5-30 Детальніше Навчання трейдингу Житомир Рівень: початковий середній профі К-сть уроків: 5-30 Детальніше Навчання трейдингу Запоріжжя Рівень: початковий середній профі К-сть уроків: 5-30 Детальніше Навчання трейдингу Херсон Рівень: початковий середній профі К-сть уроків: 5-30 Детальніше Навчання трейдингу Суми Рівень: початковий середній профі К-сть уроків: 5-30 Детальніше Навчання трейдингу Черкаси Рівень: початковий середній профі К-сть уроків: 5-30 Детальніше Навчання трейдингу Чернігів Рівень: початковий середній профі К-сть уроків: 5-30 Детальніше Чому трейдери обирають TradingInfo Навчання Форекс та криптовалюта. З нами кожен знайде курс для себе: навчання трейдингу криптовалют здобуття навичок короткотермінової і середньотермінової торгівлі алготрейдинг психологія торгівлі торгові стратегії для крипто та форекс ринку навчання торгівлі на Форексі біткоін курси форекс торгові стратегії Навчання трейдингу Команда професійних трейдерів розробляє курси виходячи зі свого досвіду зміни ринку і сучасних методик які допомагають в найкоротші терміни освоїти матеріал і вийти на новий рівень прибутку. Тебе чекає оптимальний мікс теорії і практики відсутність “водички” і всебічна підтримка наставника. Ви можете пройти навчання трейдингу Львів Київ Одеса Чернівці Харків Ужгород Вінниця Тернопіль Запоріжжя Івано-Франківськ Полтава Чернігів Черкаси Суми Луцьк Миколаїв Дніпро Кропивницький Рівне Хмельницький Житомир Херсон та онлайн. Як відомо навчання Форекс з наставником проходить швидше дає кращі результати та обходиться дешевше. Так як помилки новачків можуть коштувати їм не одного депозиту тоді як робота з досвідченим трейдером допоможе скоротити втрати в рази. Вибирайте відповідний курс і вчіться за авторською методикою. tradinginfo Все про фінансові ринки. Криптовалюта Біткоін Форекс Акції. Торгові стратегії. Торгові сигнали. Навчання трейдингу. Контакти Львів проспект В’ячеслава Чорновола 77 ЖК Платинум 380934125348 infotradinginfo.club Facebook Instagram Telegram Аналітика Аналітика валют Аналітика криптовалют Аналітика фінансових ринків Аналітика фондового ринку Індекс страху і жадібності криптовалют Таблиця прогнозу спільноти форекс Теплова карта криптовалют Форекс економічний календар Прогноз EUR/USD Прогноз GBP/USD Прогноз USD/UAH Навчання Навчання Курс Smart Money Безпечний трейдинг Блокчейн навчання Криптовалюта з чого почати Курси трейдингу онлайн Навчання по криптовалюті Навчання трейдингу Київ Навчання трейдингу Львів Навчання трейдингу Одеса Трейдинг для початківців Трейдинг криптовалют навчання Трейдинг Price Action Книги про трейдинг Основи трейдингу Словник трейдера Технічний аналіз Технічні індикатори Торгові стратегії Трейдинг Успішні трейдери Фондовий ринок Фундаментальний аналіз Криптовалюта Біткоін Блокчейн Криптовалюта Криптовалюти Криптовалютні гаманці Основи криптовалюти Словник криптотермінів Теплова карта криптовалют Торгівля криптовалютою Курс Bitcoin BTC Курс Ethereum ETH Курс Solana SOL Курс Dogecoin DOGE Курс Ripple XRP © 2024 TradingInfo. Всі права захищено. Політика конфіденційності Відмова від відповідальності Відмова від відповідальності Компанія не надає гарантій заробітку на біржах в якій би то не було формі. Компанія не займається діяльністю яка підлягає ліцензуванню. Компанія не займається брокерським обслуговуванням. Компанія не займається довірчим управлінням. Компанія не залучає позики у населення. Open chaty
By AnthonyJosse April 10, 2025 - 4:57 am
Устали от непрекращающейся уборки? Доверьте это экспертам Наша уборочная компания сервисирует высококачественные услуги по уборке квартир чтобы вы могли наслаждаться чистотой и уютом без дополнительных забот. Мы используем только безопасные и действующие средства а наша команда профессиональных специалистов гарантирует идеальный результат. Тапайте https://ubork-kompan24.ru Запишитесь на прием по уборке прямо сейчас также получите скидку в размере 10 от стоимости на первое посещение Позвольте себе больше свободного времени для главных дел и релаксации. Звоните нам или оставляйте заявки — чистота вашего дома в проверенных руках
By Jason April 10, 2025 - 5:09 am
Наш сайт предлагает вам лучшие финансовые решения! Мы предоставляем разнообразные финансовые продукты, включая кредиты, банковские карты и займы, чтобы помочь вам достигать ваших целей и воплощать мечты. Планируете купить жилье, автомобиль или оплатить учебу? Наши кредитные программы созданы специально для вас. Оформите кредит на нашем сайте всего за несколько минут, выбрав подходящие условия и срок погашения. Наши банковские карты предоставляют не только удобство безналичных платежей, но и множество бонусов и привилегий. Оформите карту онлайн и получайте кэшбэк, скидки у партнеров и участие в программе лояльности. Мы предлагаем карты с различными лимитами и условиями обслуживания, чтобы вы могли выбрать оптимальный вариант для себя. Если вам не хватает средств до зарплаты или на непредвиденные расходы, наши займы – это быстрое и удобное решение. Мы предлагаем прозрачные условия и быстрое одобрение заявок, чтобы вы могли решить свои финансовые вопросы без задержек. Наши преимущества: простота и удобство – оформление заявки онлайн за считанные минуты; надежность и прозрачность – честные условия без скрытых комиссий; индивидуальный подход – учет ваших личных обстоятельств. Не упустите шанс улучшить свою финансовую ситуацию. Оформите кредит, банковскую карту или займ на нашем сайте уже сегодня и наслаждайтесь всеми преимуществами работы с надежным финансовым партнером. Сделайте шаг к своим мечтам на нашем сайте!
Банк Зенит – кредитная карта в Братске
By JosephFal April 10, 2025 - 6:27 am
Радуйтесь чистоте вашего дома без лишних усилий Наша клининговая компания в Санкт-Петербурге предлагает первоклассные услуги уборки: от традиционной чистки до специализированных процедур. Мы сознаем как важно возвращаться в комфортное и аккуратное пространство поэтому наши профессионалы используют только безопасные и эффективные средства. Заходите https://spb24uslugi.ru/ Поручите заботу о чистоте вашего дома нам и наслаждайтесь временем с любимыми с удовольствием Оформляйте заказ уборку у нас — и вы позабудете о пыли и неразберихе.
By Waynegon April 10, 2025 - 7:36 am
Vega Casino – emerges as a notable contender in the crowded online casino landscape, promising players a sophisticated and immersive gaming experience. Its sleek, modern design immediately captures attention, mirroring the glitz and glamour associated with its namesake. The intuitive interface ensures seamless navigation, allowing users to effortlessly explore the vast array of games on offer.
By MilaWaype April 10, 2025 - 12:16 pm
предметная съемка товаров для маркетплейса 19
By Weapondba April 10, 2025 - 7:51 pm
Many calligraphers have acquired
By MichaelVat April 10, 2025 - 8:37 pm
Kraken — это передовая платформа для anonymous purchases в даркнете. Если вы хотите найти services, которые не доступны в обычной сети, вам стоит обратить внимание на этот ресурс. Для входа на платформу вы можете использовать working mirrors, которые обеспечивают constant access. На Kraken представлен широкий спектр товаров и услуг, которые можно купить с полным соблюдением конфиденциальности. Уникальность сайта заключается в том, что он предлагает intuitive interface и высокий уровень безопасности, что делает его идеальным выбором для тех, кто ищет надежный способ совершения сделок в сети.
вход vk at
By Gregory April 11, 2025 - 1:50 am
Наш сайт предлагает вам лучшие финансовые решения! Мы предоставляем разнообразные финансовые продукты, включая кредиты, банковские карты и займы, чтобы помочь вам достигать ваших целей и воплощать мечты. Планируете купить жилье, автомобиль или оплатить учебу? Наши кредитные программы созданы специально для вас. Оформите кредит на нашем сайте всего за несколько минут, выбрав подходящие условия и срок погашения. Наши банковские карты предоставляют не только удобство безналичных платежей, но и множество бонусов и привилегий. Оформите карту онлайн и получайте кэшбэк, скидки у партнеров и участие в программе лояльности. Мы предлагаем карты с различными лимитами и условиями обслуживания, чтобы вы могли выбрать оптимальный вариант для себя. Если вам не хватает средств до зарплаты или на непредвиденные расходы, наши займы – это быстрое и удобное решение. Мы предлагаем прозрачные условия и быстрое одобрение заявок, чтобы вы могли решить свои финансовые вопросы без задержек. Наши преимущества: простота и удобство – оформление заявки онлайн за считанные минуты; надежность и прозрачность – честные условия без скрытых комиссий; индивидуальный подход – учет ваших личных обстоятельств. Не упустите шанс улучшить свою финансовую ситуацию. Оформите кредит, банковскую карту или займ на нашем сайте уже сегодня и наслаждайтесь всеми преимуществами работы с надежным финансовым партнером. Сделайте шаг к своим мечтам на нашем сайте!
Кредит Ипотека в Владимире
By AlyProof April 11, 2025 - 1:52 am
гол футзал
By Jeffreymaw April 11, 2025 - 4:29 am
https://riobet-kazino.ru
By 2025iplImpum April 11, 2025 - 7:09 am
dont think anything _________________ indian premier league
By maryannOpeft April 11, 2025 - 7:30 am
Внимание если авто mailsco.online обзоры. Это важно для выбора.
By PeterRah April 11, 2025 - 9:16 am
El codigo de promocion de 1xBet le permite recibir hasta $130 en bono cuando realiza su primer deposito en 2025. 1xBet es una popular casa de apuestas en linea que ofrece una amplia seleccion de apuestas deportivas y juegos de azar. Para los nuevos usuarios, 1xbet ofrece un regalo de bienvenida especial en forma de codigo promocional. Los codigos promocionales son codigos especiales que le permiten obtener bonos adicionales al registrarse o realizar apuestas en el sitio.
Codigo promocional 1xbet: Bono del 100 % hasta 130 $/€ – http://centroculturalrecoleta.org/blog/pages/?c_digo_promocional_165.html
Codigo promocional 1xBet 2025 Reclame su bono de bienvenida del 100% hasta €/$130. Todo lo que tiene que hacer es copiar el codigo promocional e ingresarlo durante el registro, activara todas las ofertas de bonificacion de 1xbet. Los codigos promocionales publicados en nuestro sitio web solo se pueden utilizar durante el registro, contribuyen a la recepcion de un bono para nuevos jugadores. Todos los codigos de bonificacion se proporcionan de forma gratuita.
By Lavillweids April 11, 2025 - 10:33 am
iron nickel rod fe 54 ni 46 diamete – купить онлайн в интернет-магазине химмед Tegs: mission microrna hsa mir 596 – купить онлайн в интернет-магазине химмед mission microrna hsa mir 596 – купить онлайн в интернет-магазине химмед mission microrna hsa mir 597 – купить онлайн в интернет-магазине химмед iron nickel rod fe 54 ni 46 diamete – купить онлайн в интернет-магазине химмед https://chimmed.ru/products/iron-nickel-rodfe-54-ni-46-diamete-id=4195271
By WalterEcoli April 11, 2025 - 10:58 am
Our promo code 1XBET 2025 helps to unlock an exclusive 1XBET welcome bonus for new players, and this guide will provide the information you need on how to maximize it. It includes an explanation of how to get and claim promo code 1XBET deals, presents the registration process and other top features like the 1XBET app. So let’s start with what is the latest promo code for 1XBET?
A boosted welcome bonus is offered at 1XBET for players using our code promo 1XBET 2025 while signing up. The bonus includes an extra 30% on the sports welcome bonus after the first deposit and a generous casino package with bonus cash and free spins with the first four deposits. In the following section, you can find the explanation how to use the 1XBET promo code and the presentation of 1XBET bonus offers and promotions for 2025 you can claim with our 1XBET promo code 2025. 1xbet Promo Code Welcome Bonus Up To €/$130
https://cascadeclimbers.com/content/pgs/1xbet_free_promo_code_bonus.html
With the 1XBET bonus code 2025, you access exclusive bonuses for sports and casino. Grab an enhanced 130% sports betting bonus up to €130, and a casino package of up to €1950 + 150 free spins! The code has to be entered in the registration form.
By Josephvaf April 11, 2025 - 11:09 am
INCREDIBLY SENSIBLE SHAFTING DOLL WITH METAL SKELETON!
Pet the modification – just like a legitimate ally!
ULTRA-SOFT SKIN that consummately mimics the touch of real human husk – indistinguishable!
Anatomically on the mark proportions, at best like a real mate – every curve in precise harmony!
WHY IS THIS DOLL EVERY HANDCUFFS’S DREAM?
– SUPPLE METAL CONSTRUCT – holds any location you can presume!
– 100% ALL RIGHT – non-toxic medical-grade apparatus, certified by CCIC – no other-worldly smells, lately simple pleasure!
– MAXIMUM VERSATILITY – enjoy vaginal, anal, verbal, mamma play and anything else you desire!
– RELAXED SUSTENANCE – unpretentious to harbour clean and native!
INCOMPATIBLE PROFFER! Hear yours now at the best clothes figure – while stocks last TOP-RATED Hold dear Doll on AliExpress with BLUSTER REVIEWS!!
GET YOUR SELF-INDULGENT REFERENCE BOOK WITHOUT DELAY!
Discreet withdrawn packaging – 100% solitude guaranteed!
This isn’t just a doll – it’s the fulfillment of your deepest desires! Don’t young woman gone from – **harmony now and sagacity uttermost happiness!
By Eric April 11, 2025 - 4:50 pm
Добро пожаловать на наш сайт! Мы предлагаем широкий выбор финансовых продуктов: кредиты, банковские карты и займы, чтобы помочь вам реализовать ваши мечты и достичь поставленных целей. Планируете купить дом, машину или оплатить обучение? Наши кредитные программы идеально подходят для любых нужд. Оформите кредит на нашем сайте за считанные минуты, выбрав лучшие условия и сроки погашения. Наши банковские карты обеспечивают удобство безналичных платежей и множество бонусов. Получите кэшбэк, скидки у партнеров и участвуйте в программе лояльности. Выберите карту с оптимальными лимитами и условиями обслуживания. Не хватает денег до зарплаты или на неожиданные расходы? Наши займы – это быстрый и удобный способ получить необходимую сумму. Мы предлагаем прозрачные условия и мгновенное одобрение заявок, чтобы вы могли решить свои финансовые вопросы без задержек и лишних хлопот. Не упустите возможность улучшить свою финансовую ситуацию! Оформите кредит, банковскую карту или займ на нашем сайте уже сегодня и наслаждайтесь всеми преимуществами сотрудничества с надежным финансовым партнером. Переходите на наш сайт и сделайте шаг к своим мечтам!
Т-Банк – кредитная карта Платинум в Прокопьевске
By Sprinklervbm April 11, 2025 - 4:58 pm
from a printed book reproduction
By PeterRomia April 11, 2025 - 8:14 pm
Kraken — это одна из ведущих площадок для безопасных и анонимных покупок в даркнете. Здесь вы можете найти rare goods, доступные только через working mirrors. Для того чтобы попасть на сайт, используйте официальную ссылку. Kraken гарантирует high level of security и secure transactions для каждого пользователя.
kraken onion ссылка
By Lavillweids April 12, 2025 - 12:28 am
methyl 6 acetamido 4 hydroxyquinoline 2 carboxylate 96 – купить онлайн в интернет-магазине химмед Tegs: polyethylene low density ldpe rod – купить онлайн в интернет-магазине химмед polyethylene low density ldpe rod – купить онлайн в интернет-магазине химмед polyethylene low density ldpe rod – купить онлайн в интернет-магазине химмед methyl 6 acetyl 2 amino 4 5 6 7 tetrahydrothieno 2 3 c pyridine 3 carboxylate – купить онлайн в интернет-магазине химмед https://chimmed.ru/products/methyl-6-acetyl-2-amino-4567-tetrahydrothieno23-cpyridine-3-carboxylate-id=4348044
By AngelOwnex April 12, 2025 - 4:12 am
Meteora Insights https://trendingmeteora.wordpress.com is your go-to hub for everything related to Meteora on Solana — from advanced DLMM features and automated earning vaults to profit-oriented DeFi approaches optimized low-slippage trades and liquidity provision rewards. Explore detailed tutorials analytics and exclusive alpha on the smartest liquidity routes LP automation tactics and methods to earn sustainable income in the rapidly expanding Solana DeFi ecosystem.
By David April 12, 2025 - 7:27 am
Наш сайт предлагает вам лучшие финансовые решения! Мы предоставляем разнообразные финансовые продукты, включая кредиты, банковские карты и займы, чтобы помочь вам достигать ваших целей и воплощать мечты. Планируете купить жилье, автомобиль или оплатить учебу? Наши кредитные программы созданы специально для вас. Оформите кредит на нашем сайте всего за несколько минут, выбрав подходящие условия и срок погашения. Наши банковские карты предоставляют не только удобство безналичных платежей, но и множество бонусов и привилегий. Оформите карту онлайн и получайте кэшбэк, скидки у партнеров и участие в программе лояльности. Мы предлагаем карты с различными лимитами и условиями обслуживания, чтобы вы могли выбрать оптимальный вариант для себя. Если вам не хватает средств до зарплаты или на непредвиденные расходы, наши займы – это быстрое и удобное решение. Мы предлагаем прозрачные условия и быстрое одобрение заявок, чтобы вы могли решить свои финансовые вопросы без задержек. Наши преимущества: простота и удобство – оформление заявки онлайн за считанные минуты; надежность и прозрачность – честные условия без скрытых комиссий; индивидуальный подход – учет ваших личных обстоятельств. Не упустите шанс улучшить свою финансовую ситуацию. Оформите кредит, банковскую карту или займ на нашем сайте уже сегодня и наслаждайтесь всеми преимуществами работы с надежным финансовым партнером. Сделайте шаг к своим мечтам на нашем сайте!
Все займы за час в Долгопрудном
By steelersfanwhild April 12, 2025 - 4:40 pm
отитеЖелаетеМечтаете получить есплатныйдаровойхалявный NFT? ?? Участвуйте в озыгрышеакциилотерее от Mega M3GA-AT ?? Подробнее https://megaweb2.top/eenD181tD180uktseeya-myega/index.htm #megaweb3 #megaweb15-at #megaweb8 #megaweb14-at #M3GA-AT #M3GA-GL
By Daniel April 12, 2025 - 9:51 pm
Наш сайт предлагает вам лучшие финансовые решения! Мы предоставляем разнообразные финансовые продукты, включая кредиты, банковские карты и займы, чтобы помочь вам достигать ваших целей и воплощать мечты. Планируете купить жилье, автомобиль или оплатить учебу? Наши кредитные программы созданы специально для вас. Оформите кредит на нашем сайте всего за несколько минут, выбрав подходящие условия и срок погашения. Наши банковские карты предоставляют не только удобство безналичных платежей, но и множество бонусов и привилегий. Оформите карту онлайн и получайте кэшбэк, скидки у партнеров и участие в программе лояльности. Мы предлагаем карты с различными лимитами и условиями обслуживания, чтобы вы могли выбрать оптимальный вариант для себя. Если вам не хватает средств до зарплаты или на непредвиденные расходы, наши займы – это быстрое и удобное решение. Мы предлагаем прозрачные условия и быстрое одобрение заявок, чтобы вы могли решить свои финансовые вопросы без задержек. Наши преимущества: простота и удобство – оформление заявки онлайн за считанные минуты; надежность и прозрачность – честные условия без скрытых комиссий; индивидуальный подход – учет ваших личных обстоятельств. Не упустите шанс улучшить свою финансовую ситуацию. Оформите кредит, банковскую карту или займ на нашем сайте уже сегодня и наслаждайтесь всеми преимуществами работы с надежным финансовым партнером. Сделайте шаг к своим мечтам на нашем сайте!
Кредит под залог недвижимости от «Совкомбанка» в Владикавказе
By Arisha11pn April 13, 2025 - 1:38 am
Hello colleagues Hi. A 11 great website 1 that I found on the Internet. Check out this website. Theres a great article there. https://reviveus2016.com/arbitrage-betting/individual-sports-vs-team-sports-betting-whats-the-difference/ There is sure to be a lot of useful and interesting information for you here. Youll find everything you need and more. Feel free to follow the link below.
By Brianquero April 13, 2025 - 8:55 am
https://writer-demo.boshka.eu/index.php/2025/03/31/online-slots-vs-physische-spielautomaten-3/
By Ascentwhw April 13, 2025 - 9:20 am
Since the era of Charlemagne
By Marshallprp April 13, 2025 - 9:21 am
handwritten books were made
By Mark April 13, 2025 - 1:47 pm
Ищете лучшие финансовые решения? Наш сайт предлагает широкий ассортимент кредитов, банковских карт и займов, чтобы помочь вам достигать ваших целей и воплощать мечты. Хотите купить жилье, автомобиль или оплатить учебу? Наши кредитные программы подходят для любых нужд. Оформите кредит на нашем сайте за несколько минут, выбрав лучшие условия и сроки погашения. Наши банковские карты обеспечивают удобство безналичных платежей и множество бонусов. Получите кэшбэк, скидки у партнеров и участвуйте в программе лояльности. Выберите карту с оптимальными лимитами и условиями обслуживания для себя. Если вам не хватает денег до зарплаты или на неожиданные расходы, наши займы – это быстрое и удобное решение. Мы предлагаем прозрачные условия и мгновенное одобрение заявок, чтобы вы могли решить свои финансовые вопросы без задержек и лишних хлопот. Наши преимущества: простота и удобство – оформление заявки онлайн за считанные минуты; надежность и прозрачность – честные условия без скрытых комиссий; индивидуальный подход – учет ваших личных обстоятельств. Не упустите возможность улучшить свою финансовую ситуацию. Оформите кредит, банковскую карту или займ на нашем сайте уже сегодня и наслаждайтесь всеми преимуществами сотрудничества с надежным финансовым партнером. Сделайте шаг к своим мечтам на нашем сайте!
Дебетовая карта Premium в Новочеркасске
By Joshua April 14, 2025 - 3:38 am
Наш сайт предлагает вам лучшие финансовые решения! Мы предоставляем разнообразные финансовые продукты, включая кредиты, банковские карты и займы, чтобы помочь вам достигать ваших целей и воплощать мечты. Планируете купить жилье, автомобиль или оплатить учебу? Наши кредитные программы созданы специально для вас. Оформите кредит на нашем сайте всего за несколько минут, выбрав подходящие условия и срок погашения. Наши банковские карты предоставляют не только удобство безналичных платежей, но и множество бонусов и привилегий. Оформите карту онлайн и получайте кэшбэк, скидки у партнеров и участие в программе лояльности. Мы предлагаем карты с различными лимитами и условиями обслуживания, чтобы вы могли выбрать оптимальный вариант для себя. Если вам не хватает средств до зарплаты или на непредвиденные расходы, наши займы – это быстрое и удобное решение. Мы предлагаем прозрачные условия и быстрое одобрение заявок, чтобы вы могли решить свои финансовые вопросы без задержек. Наши преимущества: простота и удобство – оформление заявки онлайн за считанные минуты; надежность и прозрачность – честные условия без скрытых комиссий; индивидуальный подход – учет ваших личных обстоятельств. Не упустите шанс улучшить свою финансовую ситуацию. Оформите кредит, банковскую карту или займ на нашем сайте уже сегодня и наслаждайтесь всеми преимуществами работы с надежным финансовым партнером. Сделайте шаг к своим мечтам на нашем сайте!
Все дебетовые карты в Череповце
By Thomasliawl April 14, 2025 - 4:16 am
Dokumenty kolekcjonerskie to niezwykle ciekawy obszar dla milosników historii i kultury materialnej. Obejmuje szeroki zakres artefaktów takich jak stare paszporty dowody osobiste prawa jazdy bilety czy legitymacje. Kolekcjonowanie takich dokumentów moze byc pasjonujacym hobby pozwalajacym na zglebianie historii i obyczajów róznych epok. Jednakze ze wzgledu na swój charakter dokumenty te budza równiez pewne kontrowersje szczególnie w kontekscie ich ewentualnego wykorzystania w sposób niezgodny z prawem. Historia dokumentów kolekcjonerskich Kolekcjonowanie dokumentów ma swoje korzenie w XIX wieku kiedy to zainteresowanie historia i archeologia zaczelo rosnac wsród zamozniejszych warstw spolecznych. Z czasem obok starozytnych rekopisów i ksiazek pojawilo sie równiez zainteresowanie dokumentami o bardziej wspólczesnym charakterze takimi jak bilety z wydarzen kulturalnych legitymacje czy inne przedmioty zwiazane z codziennym zyciem. W XX wieku zwlaszcza po I wojnie swiatowej dokumenty takie jak paszporty czy dowody osobiste zaczely byc postrzegane jako cenne pamiatki rodzinne a takze interesujace obiekty dla kolekcjonerów. Ich wartosc wynikala nie tylko z ich rzadkosci ale takze z kontekstu historycznego w jakim powstaly i byly uzywane. Wartosc dokumentów kolekcjonerskich Wartosc dokumentów kolekcjonerskich zalezy od wielu czynników takich jak ich stan wiek rzadkosc oraz historyczne znaczenie. Na przyklad paszport z okresu miedzywojennego nalezacy do znanej postaci historycznej moze osiagnac na aukcjach wysoka cene. Z kolei bilety z waznych wydarzen sportowych czy koncertów moga byc poszukiwane przez kolekcjonerów z calego swiata. Wartosc dokumentów czesto wzrasta gdy sa one zwiazane z waznymi momentami w historii takimi jak wojny rewolucje czy zmiany polityczne. Na przyklad dokumenty z czasów PRL-u takie jak legitymacje partyjne czy przepustki graniczne moga byc szczególnie cenione przez kolekcjonerów zainteresowanych historia Polski. czytaj dalej https://dobreplastiki.com/pl/
By trustgas April 14, 2025 - 10:20 am
Купить шампуни онлайн Ульяновск ХХХ https://trustgas.ru/ Всёгда лучшая продукция в наличии Только онлайн 16/03/2025
By user-976781 April 18, 2025 - 7:46 am
awesome